
2023-12-16 12:54

为了简单起见, 本节我们从(按值调用的)lambda演算开始, 以下是句法.

然后是解释器, 现在延续也成为其参数.

实际上, 这就相当于对于原本的直接的解释器进行延续传递风格变换.
这个解释器的闭包和延续均以函数表示, 现在我们考虑将其转换为更加传统的数据结构, 这将使原本模糊的地方变得清晰起来.

从现在起, 我们开始考虑稍微复杂一些的语言, 即2.5节带有定义递归过程结构的语言.
不过, 我们将对于程序的结构作出一些改变. 首先我们将每个参数都变为全局的, 并使用赋值以在过程之间交流信息. 而且, 对于主要过程的调用都将出现在「尾位置」, 这等价于goto, 即控制的直接移交. (到本节末, 读者应该能够理解这句陈述的含义.) 于是, 这个程序的控制结构将非常类似于在一个汇编语言中编写解释器. 还有一个小小的观察, 实际上读者应该注意到延续可以安排成栈的结构, 而且其可以被视为编程语言运行时的堆栈的抽象化. (对于低层次行为的理解不必停留于低层次, 而可以通过更高层次的概念进行演绎.)
鉴于程序的长度, 我们逐块阅读.

这是所有全局变量的定义, 其中CLO即closure, CTX即context (即continuation), 以及栈的实现.

initialize!为求值做准备.

INTERP是解释器的主体. 可以看到, 有的时候我们立即得到了所需要的值, 将其置于VAL之中, 接着我们APPLY_CTX以考虑接下来对于这个值做些什么; 另外一些时候, 我们需要考虑先对于某个子表达式求值, 并且给CTX添加之后要做什么的信息.

APPLY_CTX考虑对于值进行怎样的加工. 和INTERP的情况类似, 有时我们得到了想要的值, 于是需要进一步加工; 另外的时候, 我们需要考虑对于什么表达式进行求值, 并给CTX添加控制信息.
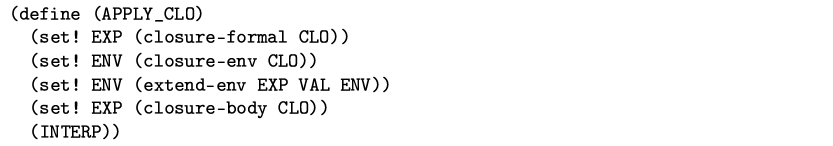
APPLY_CLO不过是应用闭包CLO于值VAL.
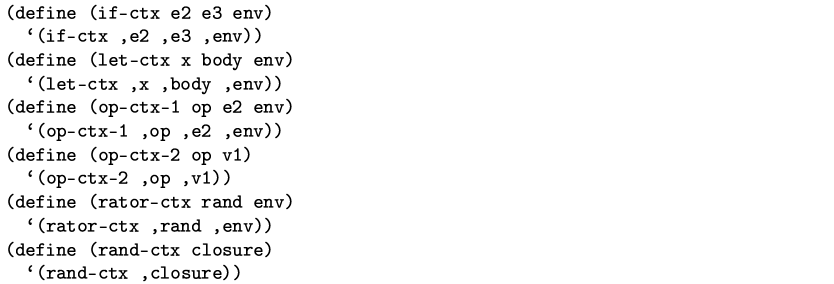
剩下的是一些简单的关于延续的数据结构的定义.
现在让我们看一个对比的例子.



从这个例子可以看到递归过程fact和<的不同性质, fact呈现了递归计算行为, 因为最大的栈深度随着输入的增长而线性地增长. 反观<, 最大的栈深度一直是3.
若我们追踪对于表达式(fact (- n 1))求值时的延续.

真正重要的原则是, 对于一个表达式的尾位置的表达式求值的延续, 应该与对于该表达式求值的延续是相等的, 这是因为尾位置的表达式的值, 就是整个表达式的值. 这也就是为什么说, 尾位置的过程调用就像goto一样, 因为无需添加任何需要做些什么的控制信息. 正是在于(fact (- n 1))没有出现在尾位置, 因而它必须记住还要做些什么.